Data engineering is rapidly evolving, such that it could still be considered an emerging field of technology. Although feature stores as a concept were introduced by Uber in 2017, they have yet to gain widespread industry adoption. This emerging technology has seen an explosion in offerings of third-party products promising to deliver the best feature store experience. However, as many data engineers are still unfamiliar with the concept, it can be easy to buy into the hype and reach for that off-the-shelf solution promising the moon. So it’s important to understand what really constitutes a feature store, at its core, to properly determine whether a given product really adds value.
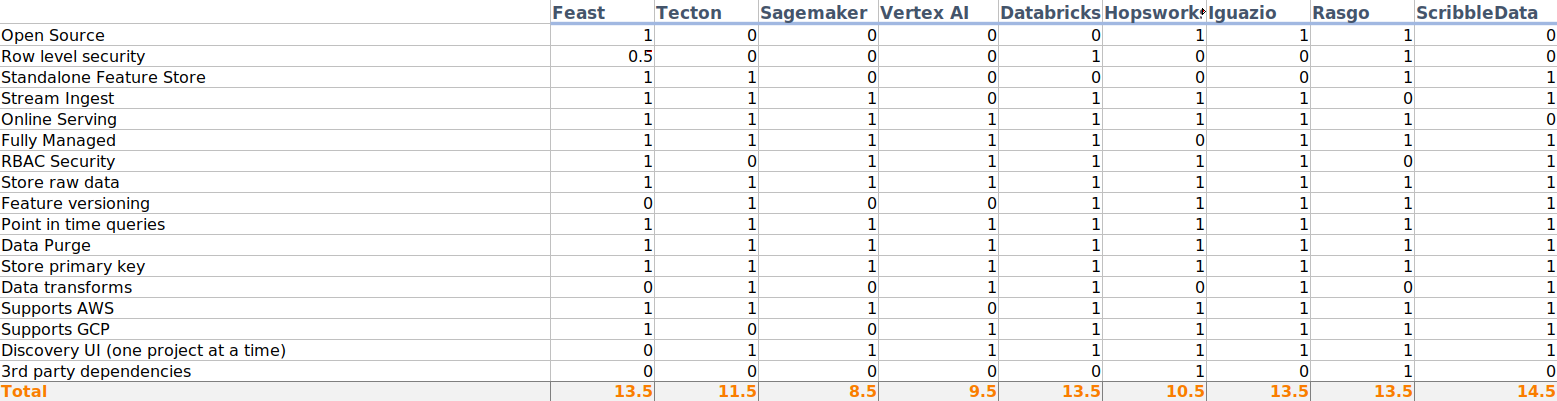
DSAL has recently been building a customer data feature store, which we’ve codenamed “Linc” – and we’ve gained a lot of valuable insights along the way! Our corporate MLOps team performed early analyses of many of the off-the-shelf solutions but eventually coalesced around an open-source product called Feast as their early recommendation.
Feast Falls Short
While building out our feature store, we made a good faith effort to utilize Feast but found that its current version suffered from some deficiencies. The advertised value just wasn’t there – and it really just passed the buck back onto data engineering teams using the product.
The primary deal breaker was that replication from the offline to the online store in Feast really isn’t sufficient to meet moderate usage needs. Feature stores, by definition, provide both “offline” and “online” data stores, which are typically OLAP and OLTP databases, respectively. OLAP databases such as Redshift and BigQuery are useful for ad hoc querying, data discovery, and point-in-time lookups from large datasets. The tradeoff is that querying the offline data store can be a bit slow. OLTP databases such as Postgres or even NoSQL offerings, on the other hand, are much more responsive, but they require that either the data be denormalized or that the consumers know exactly what to pull, making it less apt for exploration and discovery.
Feast uses the term “materialization engine” to describe replication from the offline to the online store. And the only materialization engine initially available with Feast was “local,” meaning that Feast needed to load the entire offline dataset into memory, parse it with PyArrow, convert it to Protobuf, and then upload that result to the online store. Cue the weeping and gnashing of teeth! For any dataset of reasonable size, this approach is clearly untenable.
Since we first started evaluating Feast, to their credit, they have integrated another third-party product called ByteWax to handle materialization in a much more reasonable way. But since it wasn’t available at the time, this limitation had already set us down a path of pioneering alternate options. Thus we decided to borrow a concept from the culinary world and “deconstruct” this feature store. As mentioned, a feature store by definition will define both offline and online data stores. Furthermore, the other essential parts of a feature store include the ability to do point-in-time lookups on the data in the offline store, as well as expose a REST API for fast data retrieval of the online data for ML models. Simple enough, right?
Introducing Linc
The Linc feature store is a distributed system that checks all the boxes of a conventional feature store, but it doesn’t directly use Feast or any other third-party offerings to get there. This distributed system begins with simple ingestion of the data from the vendors using Cloud Composer – which is Google’s managed service that wraps Airflow. To better explain the flow, I’ve included a simple diagram below and labeled four key stages of our pipeline.
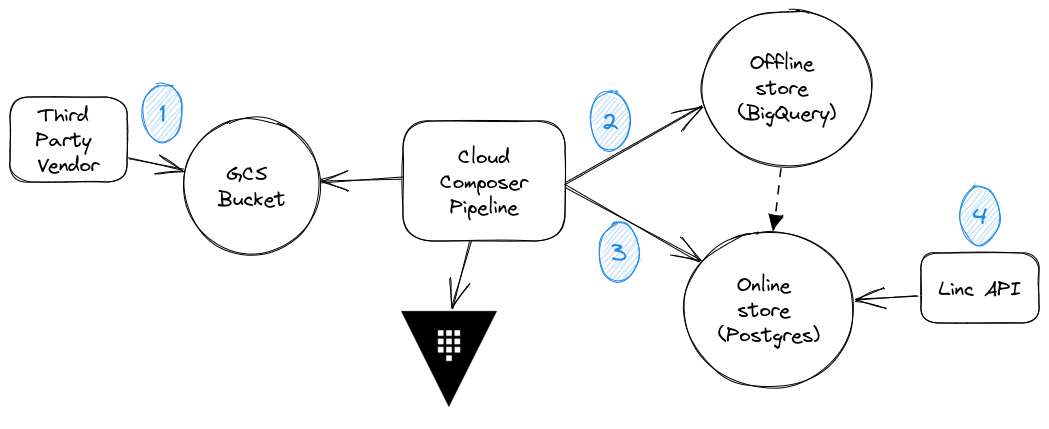
During the first stage, our third party vendor drops raw files into a shared Google Cloud Storage bucket that we own. But you could imagine that other vendors will sometimes drop their files onto FTP servers or transmit them by other means. In our case, the vendor doesn’t just drop the raw files; rather, they drop files that have undergone encryption.
Our Cloud Composer pipeline begins with the task of decrypting these third-party files. Then after stream decrypting the files, our Cloud Composer pipeline loads them directly into our offline store, BigQuery (BQ). If you’re following along with the diagram, we’ve now reached the second stage. And here we load everything, effectively in append mode. So, any new data gets added onto whatever data was already present. And since our parent company also uses BigQuery for their enterprise analytical data lake, we added a step here to replicate the same BQ tables into the data lake project.
The third stage is still within the original Cloud Composer run, but what we do is load a subset of the data into our online store, which in our case is Cloud SQL. This represents only the most recent batch of data, whereas all of the historical data, indexable by point-in-time, resides in the offline store. However, because it is a subset of the data, we represent the direct correlation with the dotted arrow on the diagram. What we actually do in code is unload the data from BigQuery into Parquet files and back into a GCS bucket. We then make use of the relatively new open-source pgpq library, to load those Parquet files directly into Postgres. But we wrap this load process with a call to GCP Batch so as to parallelize the load.
Finally, we built a simple REST API container using FastAPI to expose the online store via an endpoint. We handle authentication to this service at the infrastructure level using an Identity-Aware Proxy (IaP), which is beyond the scope of this article, but is explained in detail in our blog post on Zero Trust Networking. Our data science teams who wish to utilize the Linc feature store ultimately need access to both the online and offline stores. Scientists will pull data at various points in time from the offline store to provide a training set for their models. Once their models are ready to be served, they’ll link into Linc’s API (pun intended) to serve only the most recent data to their models.
Wrapping Up
To close the loop and make this product accessible to other teams within our enterprise, we did a little bit of reverse engineering of Feast. (Since it was already an open-source product, this was naturally pretty easy to do.) Feast generates YAML metadata files to describe the Feature Store that it presents for the purpose of publishing to a central feature registry. We simply had to mimic this proprietary YAML format to expose our feature store to the same registry.